Abstract
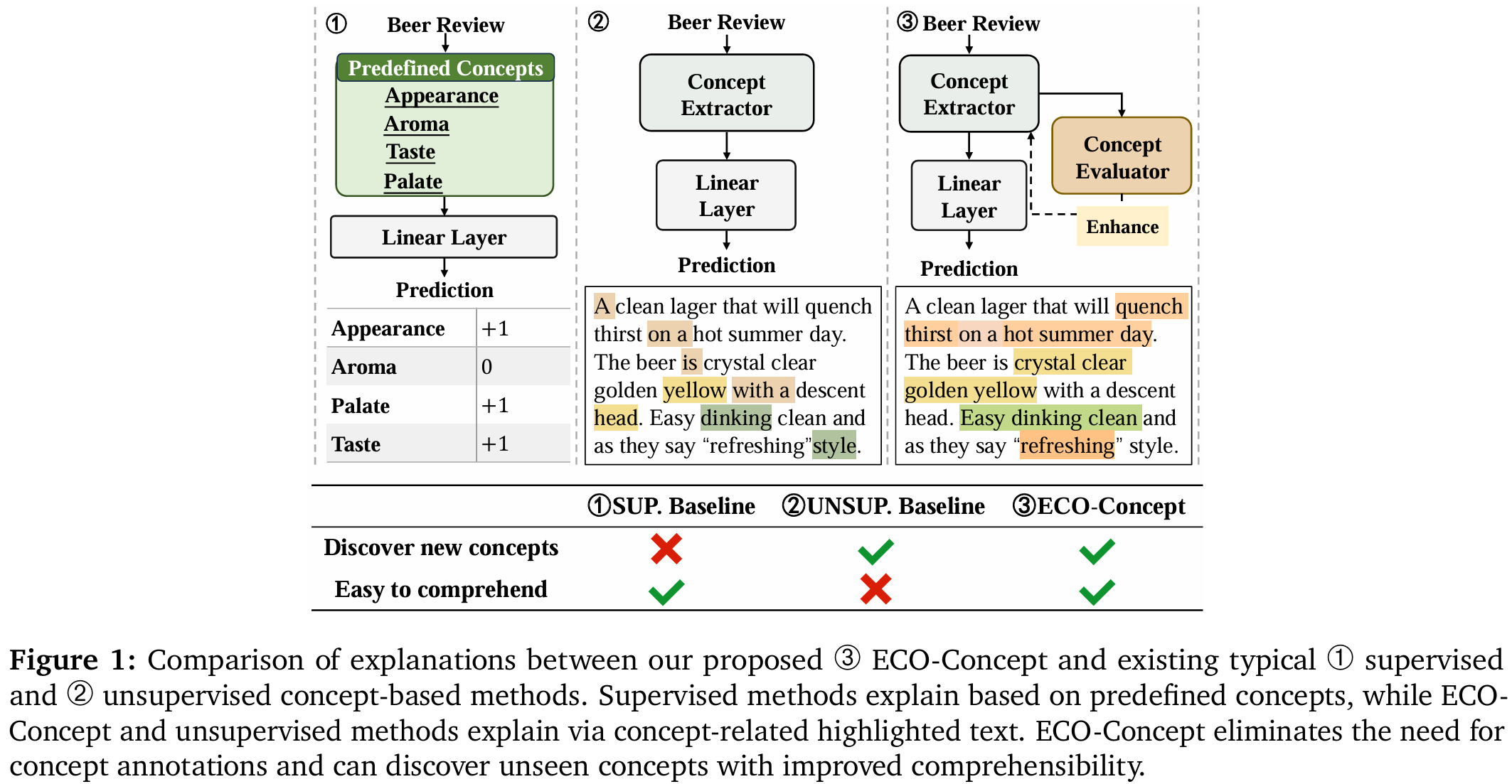
Concept-based explainable approaches have emerged as a promising method in explainable AI because they can interpret models in a way that aligns with human reasoning. However, their adaption in the text domain remains limited. Most existing methods rely on predefined concept annotations and cannot discover unseen concepts, while other methods that extract concepts without supervision often produce explanations that are not intuitively comprehensible to humans, potentially diminishing user trust. These methods fall short of discovering comprehensible concepts automatically. To address this issue, we propose ECO-Concept, an intrinsically interpretable framework to discover comprehensible concepts with no concept annotations. ECO-Concept first utilizes an object-centric architecture to extract semantic concepts automatically. Then the comprehensibility of the extracted concepts is evaluated by large language models. Finally, the evaluation result guides the subsequent model fine-tuning to obtain more understandable explanations. Experiments show that our method achieves superior performance across diverse tasks. Further concept evaluations validate that the concepts learned by ECO-Concept surpassed current counterparts in comprehensibility.
Method
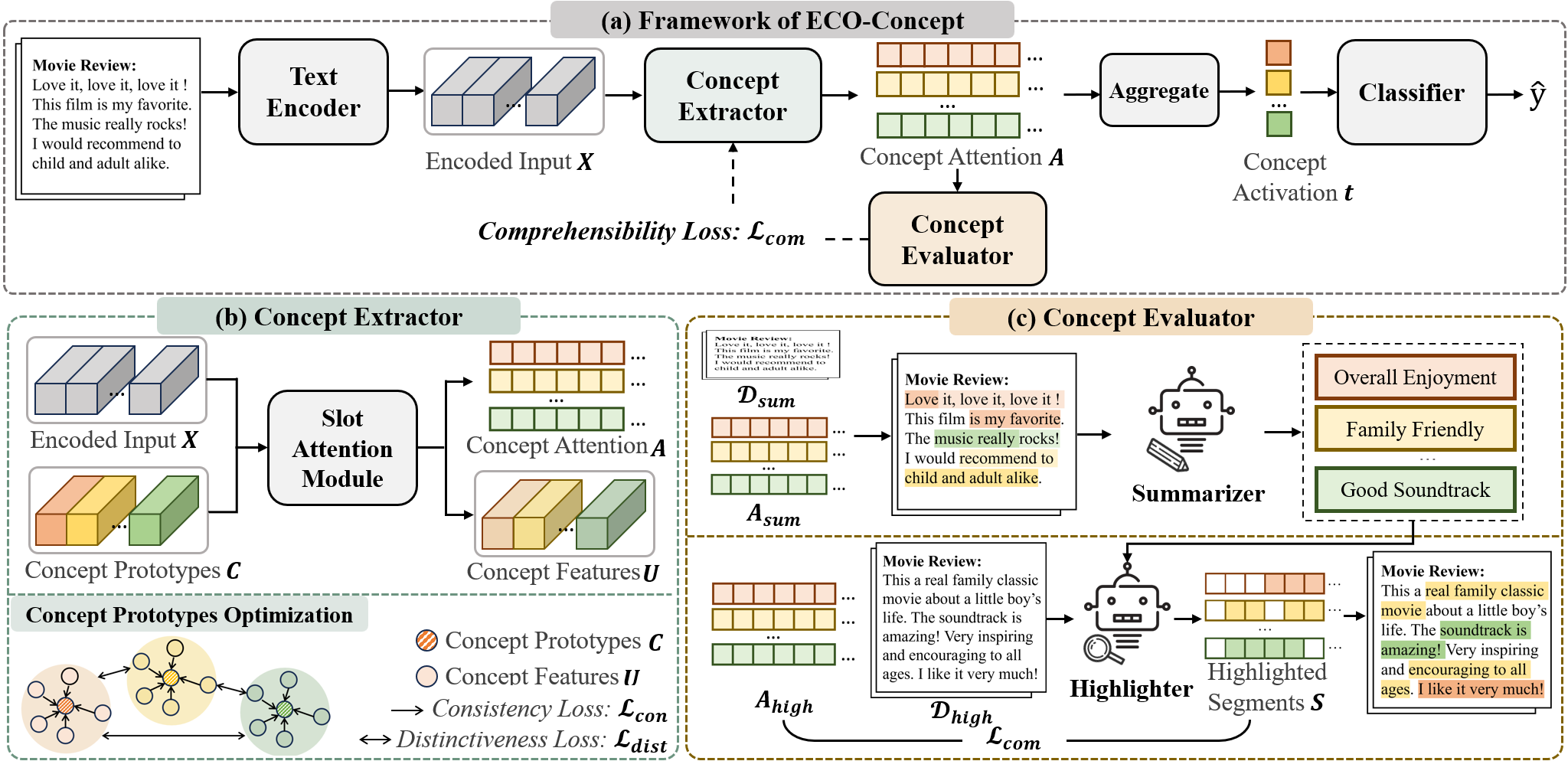
ECO-Concept consists of three modules: a concept extractor, a classifier, and a concept evaluator. The concept extractor takes the encoded text as input and generates a concept slot attention matrix by interacting with the concept prototypes. The slot attention scores across tokens are then summed and fed into the classifier for prediction. To enhance the comprehensibility of the concepts, we designed a concept evaluator that receives slot attention from the concept extractor, maps them back to the original text, and uses human proxies (here, LLMs)1 to summarize the concepts, and highlights concept related segments with additional exemplars. If a concept is easy to understand, the highlighted segments should be similar to the model’s slot attention. We use the difference between the highlighted segments and the model’s slot attention scores, considering the importance of each concept, as a comprehensibility loss. This feedback is used to make the learned concepts easier for human understanding.
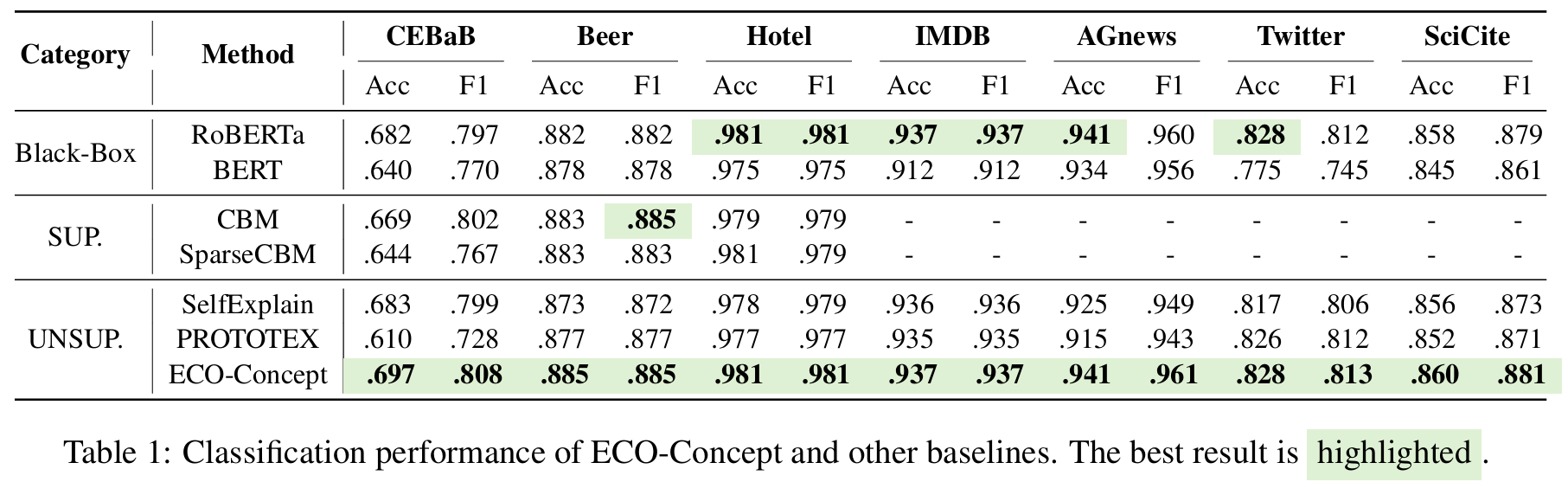
ECO-Concept achieves interpretability without compromising classification performance.
ECO-Concept achieves superior classification performance across various datasets. Compared to supervised methods, ECO-Concept achieves competitive results with no concept supervision, indicating its ability to automatically discover new concepts without compromising performance. Compared to unsupervised baselines, ECO-Concept shows significant improvements in both accuracy and F1 with pairwise t-tests at a 95% confidence level, validating the effectiveness of its conceptual representations. Moreover, ECO-Concept also has comparable or better performance compared with black-box models. This indicates that it effectively balances both task-discriminativity and concept comprehensibility, showing the potential to build interpretable models without performance trade-offs.
ECO-Concept learnes more comprehensible concept explanations.
To evaluate the comprehensibility of the concepts extracted by our method, we first define three quantitative metrics (Semantics, Distinctiveness, Consistency). Then we conduct several human evaluations, including intruder detection, subjective ratings, and forward simulatability to further assess how easily these concepts can be understood. Our ECO-Concept outperforms existing concept-based approaches in both quantitative metrics and user studies, demonstrating its effectiveness in generating human-aligned, interpretable explanations.
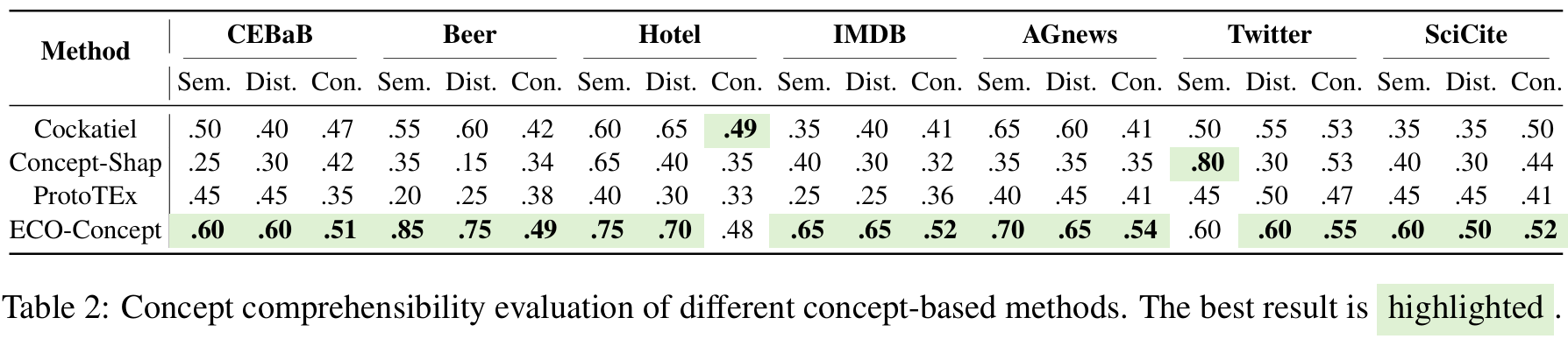
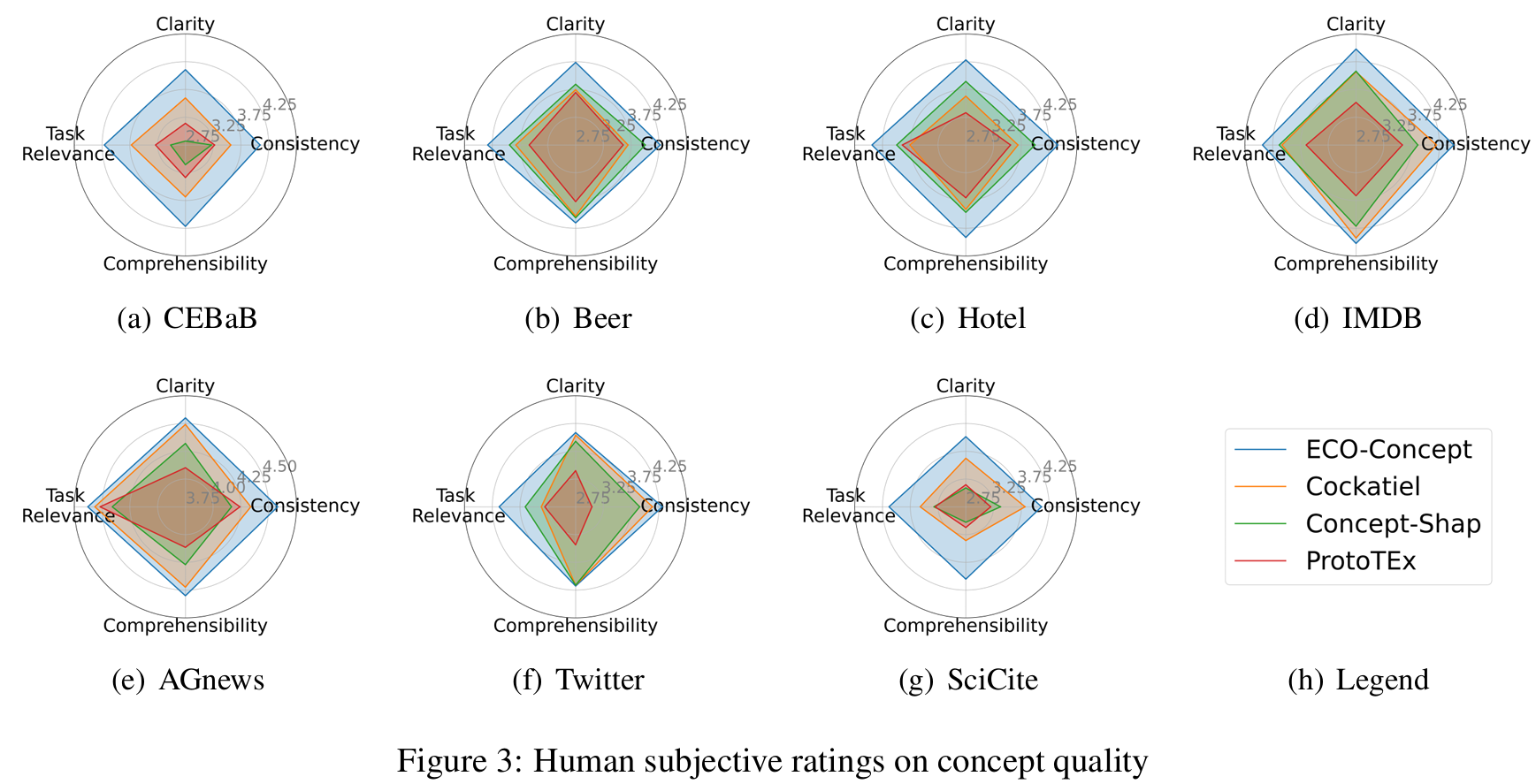
We conducted subjective rating experiments, where participants rated all the extracted concepts from multiple perspectives: Consistency, Clarity, Task Relevance, and Comprehensibility. Our method consistently achieved the highest ratings across all perspectives for each task. This result indicates that our concepts are subjectively the most comprehensible to humans and are closely aligned with the tasks. In contrast, ProtoTEx received the lowest ratings in most tasks, suggesting that traditional unsupervised self-explaining methods often struggle to balance interpretability with task performance, resulting in less intuitive concepts for human understanding.